As of yesterday, 10/22/2020, I finally graduated from the Udacity Deep Learning Nanodegree.

As I come to the conclusion of four months of waking up early every morning to study, working late nights to train new models, I realized that this course has been an emotional rollercoaster. Some lessons in the course take a day to breeze through while other lessons can take weeks. Granted, some of this boils down to my lack of knowledge in the area, but hey, that’s why I’m studying, right?
Core Curriculum
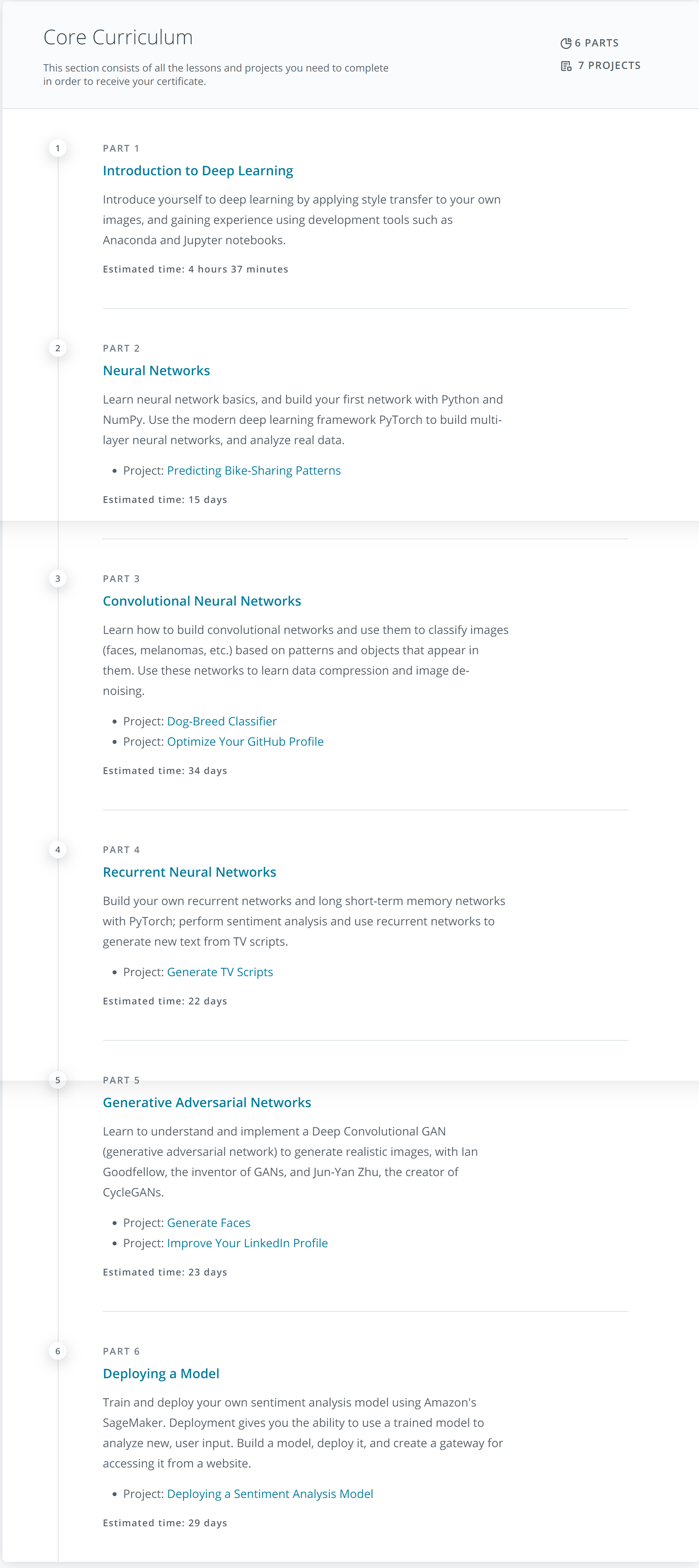
Course Assessment
I plan to write up a quick summary of what I felt about each part in the course, this post is meant to be a high level overview and thoughts.
Pros
- The course starts from the very basic concepts and builds up on it gradually. If there was honestly one thing that kept me motivated, this was it. The structure of the course and all the parts allows for continuity and flow between each lesson and it is expected that you study them in order.
- The lessons themselves provide bite-sized chunks of information. This allowed me to fill some of my free time with a lesson or two, without feeling overloaded with information. With an average lesson length of ~5 minutes, this was exactly what I needed.
- The instructors do a great job of keeping you motivated (and there’s even a guest appearance by Andrew Trask himself!)
- All projects are rooted in real world problems and the visual outcomes provide instant gratification for those who need it (like me!)
- Extracurricular and additional lessons provide some key foundational knowledge if you want to go above and beyond the functioning of existing ML frameworks and network types (There’s even a whole lesson on MiniFlow, which allows you to build a smaller, contained version of TensorFlow)
Cons
- Some lessons tend to be dense by nature and some feel light. The instructors alleviate this by breaking these dense lessons down into smaller chunks, and this takes longer. I’ve often re-watched some of the denser lessons multiple times to ensure I grasp the concept. This does, however, take time.
- The last part of the course entirely focuses on Amazon Sagemaker and building/running models on it. While it’s a good, real world ML training/inference setup in the cloud, most firms (like mine) tend to keep their training/inference local or within the building, for security reasons aside from control over the framework. When external cloud computing infrastructure is used, they’re mainly as hosts that we can build up from scratch and run the organization’s infrastructure. The hard requirement on Amazon’s SageMaker for the last project was a little unsettling.
- Uneven difficulty in projects : While Udacity (and the instructors) do a great job at defining project structure and provide the basic framework (and Jupyter Notebooks) to be successful, some projects seem to take forever to get going (with little documentation on why they don’t work) while others are simple enough to breeze through in one afternoon.
Conclusion
With all that said, the course was really great to get me on the right path to start learning the vastly complicated setups we’re seeing becoming common in the Machine Learning sphere and if given a chance, I’d definitely do it again.